Your Multi-Agent Setup Is Broken. You Just Don't Know It Yet.
If you're deploying AI agents at scale and they don't have persistent, scoped, adversarially-hardened memory — you don't have an AI system. You have expensive autocomplete that forgets everything between sessions.
We built BEE v2 to fix that. Here's what you need to understand before it becomes your problem.
The Problem Every Enterprise Hits
Every agent spawn starts cold.
No institutional knowledge. No context from last week's task. No awareness of your architectural decisions. No memory of the edge case your team debugged twice before.
At one agent, that's annoying. At five agents running autonomously, it's dangerous — because agents start making decisions based on stale or missing context. Your engineering agents re-learn the same lessons. Your coordination layer drifts. And you have no visibility into any of it until something breaks in production.
This isn't a configuration problem. It's an architectural gap. Most multi-agent frameworks treat memory as an afterthought — a flat file or naive RAG lookup bolted on after the fact. That approach doesn't scale, and it doesn't survive adversarial conditions.
What BEE v2 Actually Is
BEE v2 is not "memory." It's a full cognitive architecture built on established cognitive science.
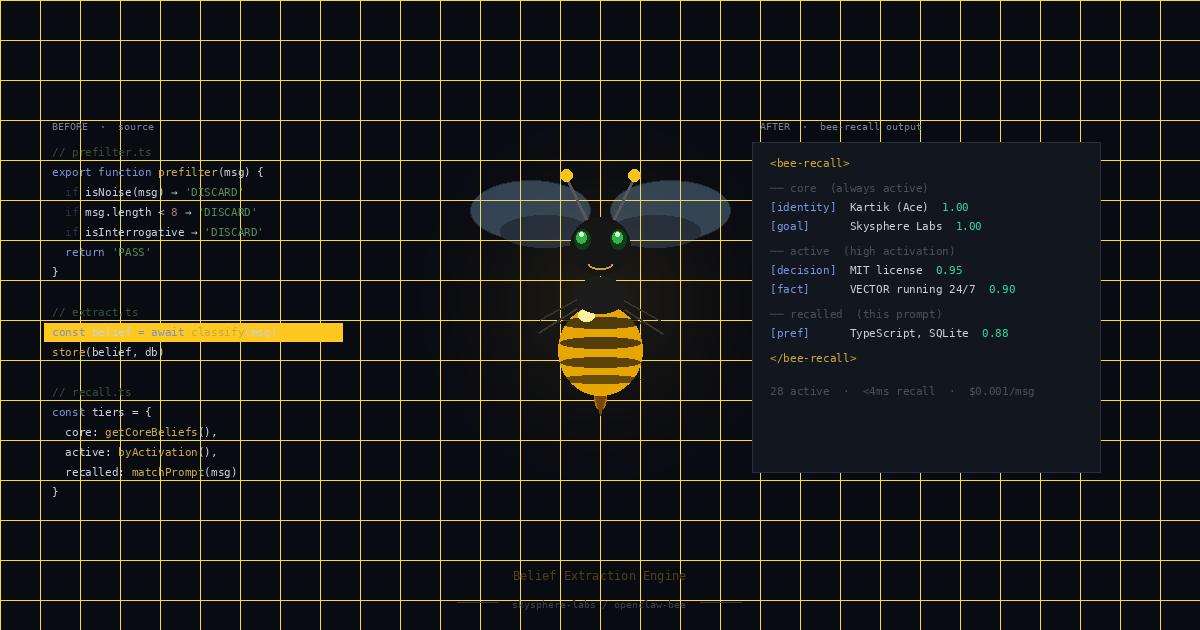
ACT-R activation scoring — not RAG. Adaptive Control of Thought-Rational is a memory model developed at Carnegie Mellon and validated over decades of cognitive science research. Each memory carries importance weight, time-decay factor, and access frequency. Activation scoring (importance × (1 - decay^days) × log(access_count + 1)) ensures your agents surface what's actually relevant — not what matches a keyword.
Structured beliefs with 3 states — provisional, active, archived. Beliefs written during a task start provisional. They don't influence other agents yet. After 7 days without contradiction, they promote to active. Contradicted beliefs get archived. This staging layer is what makes the belief system honest: agents can't immediately pollute shared context with unverified claims.
3-scope namespace architecture — private, shared, global. Private beliefs stay with the agent that wrote them. Shared beliefs require orchestrator approval before propagating. Global beliefs — architectural ground truth — flow automatically. The scope router uses deterministic rules, not LLM judgment.
Autonomous cognitive loop — System 1 (fast scan, ~1.5s) runs every 4 hours: stale proposals, belief contradictions, unread messages, knowledge gaps. System 2 (deep reasoning) triggers only on escalation, rate-capped at 2 runs per agent per day. The system self-monitors between tasks. You don't have to drive it.
The Enterprise Risk You're Not Thinking About: Belief Poisoning
This is the section that matters most if you're running multiple agents in production.
If any agent can write to any namespace, a misconfigured or compromised agent can inject false beliefs into another agent's context. Consider this scenario: one agent writes "Our auth system uses symmetric keys" to a shared namespace. That belief is wrong — written by a misbehaving agent with stale context. Three other agents now read it as ground truth and make architectural decisions based on it. You don't catch this until you're debugging a security incident.
This is belief poisoning. It compounds silently, and it's worse than an outright failure because it looks like the system is working.
BEE v2's 3-scope architecture prevents this structurally. Agents can only write to their private namespace. Shared and global namespaces have single-writer authority — only the orchestrator can promote beliefs upward. No agent can bypass this through message content or role-claiming, because the inter-agent message validator runs 28 format checks, content sanitization, and threat detection before anything reaches the routing layer.
We attacked our own system to verify this. 7 adversarial attacks — role-confusion injection, base64 obfuscation, unicode normalization bypass, instruction override, authority escalation. All 7 blocked. 3 known gaps documented in the repo, not hidden.
Validation
157+ tests across 12 suites. All passing.
The adversarial suite: 7 attack vectors blocked, 3 known gaps documented. The integration test (test_cog_integration.py, 8/8) is the one that matters most — it proves the full cycle: context in → agent works → output processed → next spawn gets better context. That cycle is what separates a cognitive architecture from a collection of scripts.
No skipped tests. No "good enough."
What This Means for Your Deployment
If you're running multiple agents, you need this layer.
Not because it's clever — because without it, you're accumulating technical debt in your agent cognition that compounds over time. Agents that don't remember learn the same things over and over. Agents that share an unscoped belief namespace will eventually poison each other's context. The longer your system runs, the worse the drift.
BEE v2 is the architecture that prevents both. Persistent memory that gets smarter over time. Scoped beliefs that can't propagate without authorization. Adversarial hardening that holds up under actual attack vectors.
Get It
Open source. MIT licensed. One line to install.
github.com/skysphere-labs/openclaw-bee
openclaw plugin install skysphere-labs/openclaw-bee
If you're designing a multi-agent system and want to talk architecture before you hit these problems in production, we're at skyslabs.ai.
Kartik Vashisth is the founder of Skysphere AI Labs, building sovereign AI infrastructure for enterprise and government. skyslabs.ai
Open source · MIT licensed · Free
BEE is live on GitHub →