OpenClaw's Memory System Is Broken. Here's How I Found Out.
I've been building on OpenClaw since it dropped 3 weeks ago. Hit every wall. This is the one that actually mattered.
OpenClaw is the most exciting agent framework I've touched. Autonomous sessions, tool use, skill files, lifecycle hooks — it's the first thing that actually felt like building a real agent and not just wrapping a chatbot.
I went deep on day one. Running it 24/7 within the first week. Built an agent called VECTOR that handles ops, tracks decisions, manages context across everything I'm working on.
And then I hit the problem that every serious OpenClaw user is going to hit, if they haven't already.
Memory. Or more specifically — the complete lack of it.
Every OpenClaw Session Starts Cold
Open a new session in OpenClaw. Your agent has no idea who you are.
Doesn't know your name. Doesn't know your stack. Doesn't know the decisions you made last week, the direction you set last month, how you like to work, what you're building toward. Every conversation is a first date. You repeat yourself constantly. The thing that was supposed to make you faster is costing you the first ten minutes of every session just getting back to where you were.
This isn't a bug. It's how OpenClaw works by default. Sessions are stateless. The only persistence mechanism that ships out of the box is MEMORY.md.
MEMORY.md — The Sticky Note Problem
If you're on OpenClaw you already know MEMORY.md. You write stuff in, the agent reads it at boot, and that's your memory system.
It works. For about two weeks.
When you have 20 entries, it's great. Agent boots, reads everything, immediately productive.
## About Me
- Name is Kartik (Ace)
- Building Skysphere Labs
- Prefer direct answers, no hedging
- Stack: TypeScript, Node, SQLite
The problem is you keep adding to it and never clean it up. Nothing in the system tells you what's stale. Nothing signals what matters more than anything else. Everything just accumulates.
By the time you hit 500+ lines — which happens faster than you think on a real project — the agent is reading a wall of equal-weight bullet points. Your current strategic direction sits next to a vendor note from a project you killed two months ago. Both get the same weight. Neither gets priority.
The responses start getting diluted. Not wrong. Just hedgier. Less sharp. Like the agent is trying to account for everything at once instead of knowing what actually matters right now.
OpenClaw's default memory is a sticky note. It breaks at scale and you won't notice until the damage is already done.
The Structured Files Phase (Also Wrong)
When the flat file breaks down, the obvious move is to add structure. That's what I did.
Split it across multiple files. MEMORY.md for general context, PROJECT.md for active work, DECISIONS.md for choices made. Tidy, organized, auditable. You could open any file and immediately understand its purpose.
Same problem. The agent reads all of them at boot, weights everything equally, dumps it all into context. More organization, identical failure mode.
The responses were still diluted. The agent still had no way to know what was current versus stale, or that certain context is only relevant to certain kinds of questions.
More files didn't fix it. I needed a different approach entirely.
I Tried to Build My Own Extractor
If you can't filter what gets read, filter what gets written. Don't let noise in at all.
I built a regex-based extractor that would watch conversations and pull out beliefs — preferences, facts, decisions — and store only the good stuff.
I ran it on one week of real conversations. 537 beliefs extracted.
I opened the database feeling pretty good.
First entry:
"ok" — identity fact — confidence: 0.85
Second:
"sure" — preference — confidence: 0.79
Deeper in:
"I'll help you with that" — stored as a fact about me
My extractor had captured the agent's own acknowledgment phrases and stored them as truths about who I am. It had classified "ok" as a core identity belief with 85% confidence.
About 80% of 537 beliefs were garbage exactly like this. The real stuff — actual preferences, actual decisions, actual context worth keeping — was buried in there somewhere. But the system had no way to tell the difference. And neither did I, scrolling through an organized landfill at midnight.
The Reframe That Changed Everything
I spent a long time thinking this was a storage problem. Better organization, more files, cleaner categories.
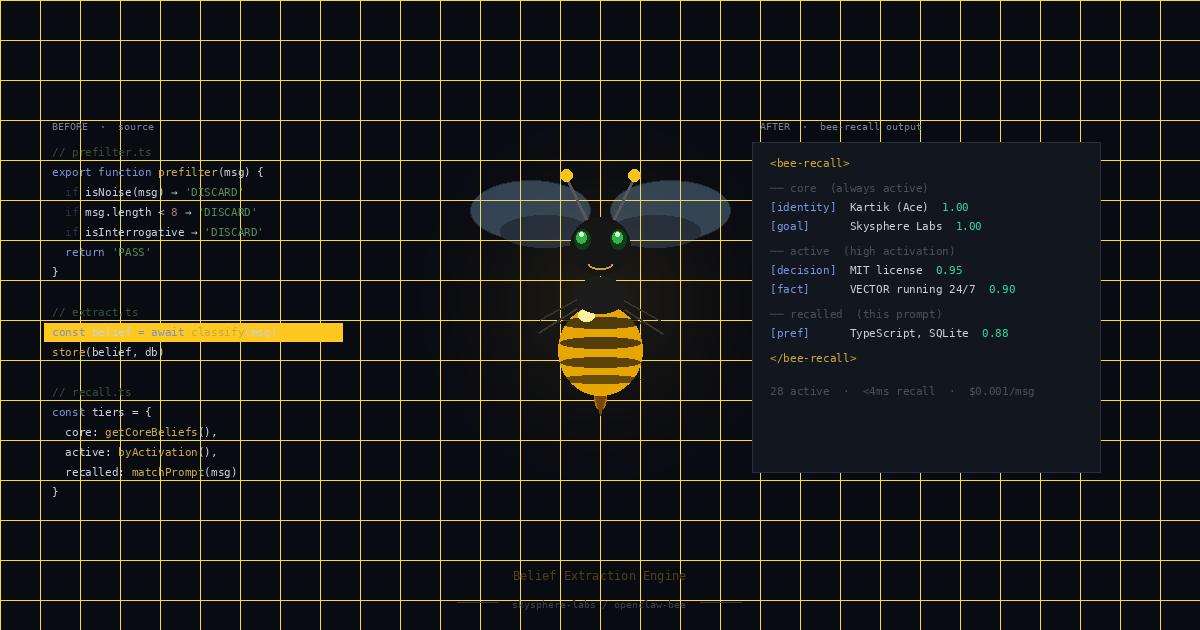
The reframe: this isn't a storage problem. It's a retrieval problem.
The goal was never to have less stuff stored. The goal was to get the right stuff in front of the agent at the right moment. Those are completely different problems, and OpenClaw's default approach doesn't solve either of them — it just gives you a place to dump things and hope.
Once I saw it that way, the solution became clear. It just took 3 more weeks to build it properly.
That's Part 2.
→ Part 2: OpenClaw Doesn't Have Real Memory. So I Built It.
The two-stage extraction pipeline, cognitive science at 1am, and the bug where my memory system started feeding itself its own outputs.
The finished system is a free open source OpenClaw plugin: skysphere-labs/openclaw-bee
Open source · MIT licensed · Free
BEE is live on GitHub →