OpenClaw Doesn't Have Real Memory. So I Built It.
Part 2 — The fix. Two-stage extraction, cognitive science, a bug that made my agent eat itself, and the free plugin that ships it all.
Quick catch-up: OpenClaw dropped 3 weeks ago. I went deep from day one. Hit the memory wall hard — flat files, structured files, a regex extractor that gave me 537 beliefs with 80% garbage. "ok" stored as an identity fact at 0.85 confidence. The insight that unlocked everything: this isn't a storage problem, it's a retrieval problem. Here's the build.
Why My Extractor Failed (And Why Yours Will Too)
After the 537-beliefs disaster, the temptation was to make the extractor smarter. Better patterns. Tighter filters.
But the problem wasn't the extractor. The problem was asking it to make judgment calls it fundamentally cannot make. No pattern matcher — no matter how clever — can tell the difference between "ok" as filler and "ok" as meaningful. They look identical on the surface. The distinction is semantic. It's about intent and context and meaning.
Regex doesn't have that. OpenClaw's default MEMORY.md append behavior doesn't have that. Nothing in the default stack has that — and that's the gap BEE fills.
The fix: stop trying to make one tool do two different jobs. Use two tools.
The Two-Stage Pipeline
Stage 1 is dumb and fast. Stage 2 is smart and cheap.
Stage 1 — the prefilter — doesn't try to understand anything. It kills obvious garbage before anything expensive sees it:
- One-word responses? Gone. "Ok", "sure", "thanks" — structurally incapable of being beliefs.
- Under 8 words? Gone. Too short to hold a subject, a predicate, and actual content.
- Questions? Gone. "What should we call this?" is not a belief about the world.
- Commands? Gone. "Run this", "show me the logs" — task instructions, not personal facts.
- Anything containing OpenClaw's memory injection markers? Gone immediately — more on why below.
What survives goes to Stage 2: an LLM call. Fast, cheap model. One job: is this a belief worth storing, and if yes, what kind?
identity → who you are, your name, your role
goal → what you're building or trying to achieve
preference → how you like to work, tool choices
decision → choices made ("going with PostgreSQL")
fact → project details, technical context
The LLM understands semantic intent. It knows "I'll help you with that" is the agent talking, not the user declaring a preference. Pattern matching can't get there. Language understanding can.
Cost: ~$0.001 per message. Basically free to run.
First pass on real OpenClaw conversations: 20/20 test cases passing. Actual beliefs coming through. No ghost residue. No filler stored as identity facts.
The 1am Research Rabbit Hole That Changed the Architecture
Clean extraction solved the garbage problem. But there was still a deeper flaw: even with good beliefs stored, everything was weighted equally.
A belief about who you are sits at the same retrieval priority as a fact about a project you killed two months ago. OpenClaw has no way to know what's current versus stale. And neither did my extractor — yet.
I was debugging late one night and fell into cognitive science research. Specifically ACT-R — Adaptive Control of Thought—Rational. A computational model of human memory from Carnegie Mellon. Four decades of research on why we remember some things and forget others.
The core idea: memories don't sit in storage with equal retrieval probability. They compete based on activation. Activation is a function of three things:
- Recency — things you've accessed recently stay fresh
- Frequency — things you keep returning to strengthen
- Context — related memories get a boost when the relevant context is present
Old memories that haven't been touched in months decay. Frequently-used memories strengthen. That's why you can't remember breakfast from three weeks ago but you can instantly recall your first-grade teacher's name if someone asks.
That's exactly what OpenClaw's memory system needs — and completely doesn't have.
I implemented activation scoring directly in SQLite:
Activation = how often this belief has been referenced − how much it has decayed over time
A belief your agent uses every session stays high. A belief that was true once and never came up again drifts toward zero. Not deleted — just stops being injected. Fade naturally. Comeback if it becomes relevant again.
The result: memory that behaves like a brain instead of a spreadsheet. Important things surface. Stale things fade. Automatically, without you managing it.
Three Tiers Beat One Dump
With activation scoring in place, the last piece was what to inject before each OpenClaw response.
Too much: context bloat. Signal buried in noise. You've rebuilt MEMORY.md with fancier math.
Too little: the agent misses important context. Starts from wrong assumptions.
The solution: three tiers, mirroring how human working memory actually operates.
┌─────────────────────────────────────────────────┐
│ TIER 1 — CORE │
│ Always injected. Every OpenClaw session. │
│ Your name. What you're building. How you work. │
│ Small, permanent, high signal. │
├─────────────────────────────────────────────────┤
│ TIER 2 — ACTIVE │
│ Recent high-activation beliefs. │
│ Decisions made this week. Current projects. │
│ Refreshed dynamically. Changes as you do. │
├─────────────────────────────────────────────────┤
│ TIER 3 — RECALLED │
│ Matched to the current message. │
│ Ask about infrastructure → infra beliefs. │
│ Ask about strategy → goal beliefs. │
│ Specific retrieval for the specific question. │
└─────────────────────────────────────────────────┘
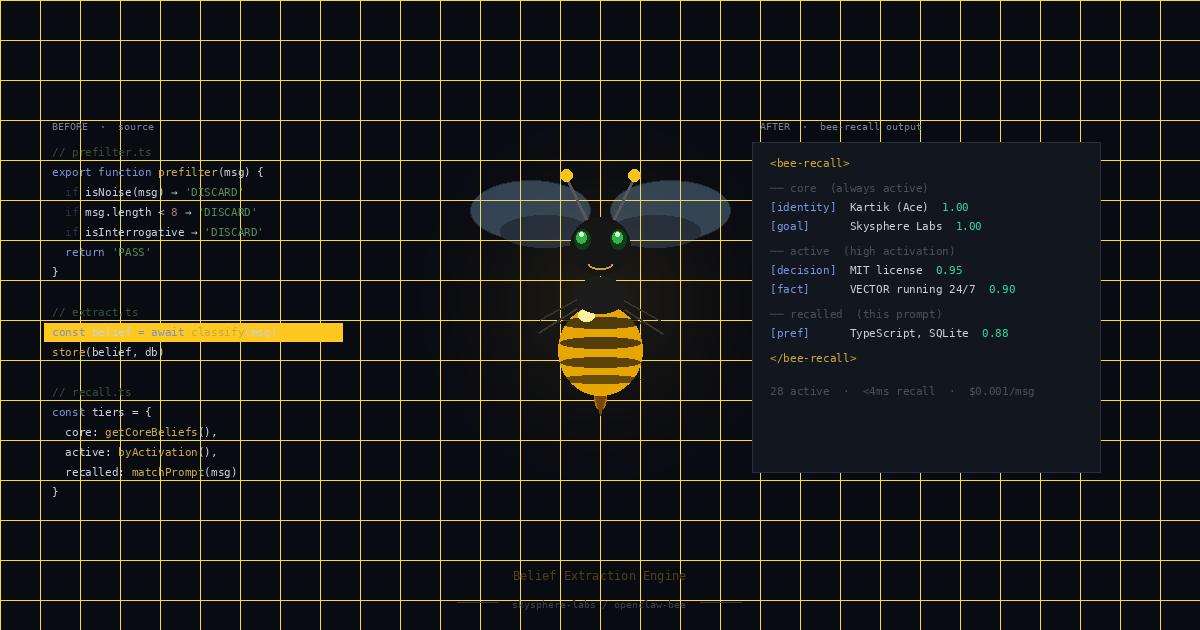
Every OpenClaw agent response now gets prepended with this:
<bee-recall>
## Core (always active)
- [identity] Chief's name is Kartik (Ace) 1.00
- [goal] Building Skysphere Labs 1.00
- [preference] Direct answers, no hedging 0.97
## Active context
- [decision] MIT license for public tooling 0.95
## Recalled (this prompt)
- [fact] BEE extraction pipeline in TypeScript 0.88
</bee-recall>
Right context. Right moment. No 500-line dump. No equal weighting.
After a few weeks through this system: 28 active beliefs. 0% garbage. Started from 537 with 80% noise.
The Bug Where My Agent Started Eating Itself
This one is funny in retrospect.
BEE was running well. Beliefs accumulating properly. Life was good.
Then I noticed the belief count climbing faster than it should.
Opened the database:
"Chief's name is Kartik (Ace)" — stored 14 times
"Chief is building Skysphere Labs" — stored 9 times
"Chief's timezone is EST" — stored 7 times
Same beliefs. Over and over. Different timestamps. Multiplying.
BEE was extracting itself.
Here's what happened: BEE injects a
So the system was feeding itself its own outputs, classifying them as fresh information, storing them again, re-injecting them next session, and extracting them again the session after. A perfect self-reinforcing loop. Automated garbage, compounding.
The fix: any message containing
The principle: any system that reads from and writes to the same stream needs explicit echo guards. The loop will not break itself. You have to break it deliberately. This applies to anything you build on top of OpenClaw's lifecycle hooks — plan for it early.
The Profile Layer
The belief database is great for the agent. Not great for humans.
Raw rows of categorized beliefs aren't friendly to read quickly. I added a synthesis layer — an LLM call that takes the active belief set and generates a short plain-language paragraph. Not a database dump. An actual summary.
After a few weeks of real conversations:
"Chief (Kartik, Ace) is the founder of Skysphere Labs, building toward a $100M outcome. Currently focused on VECTOR OS and the BEE memory plugin as Skysphere's first public release. Prefers direct communication, no hedging. Key recent decision: MIT licensing for all public tooling."
Ten-second read to know whether OpenClaw has a good model of you. Cached, async, never touches response latency.
The Numbers
Before BEE: 537 beliefs extracted, ~80% garbage
After BEE: 28 active beliefs, 0% garbage
544 archived (history, not active)
7 provisional (needs more evidence)
Recall: <4ms from SQLite
Extraction: ~$0.001 per message
Build time: 3 weeks since OpenClaw dropped
Installing It
BEE is a standalone OpenClaw plugin. One command:
openclaw plugin install skysphere-labs/openclaw-bee
Zero configuration. It creates the database, initializes the schema, starts learning immediately. Your very first session with BEE is already better than your last session without it.
8 source files. 20 tests. All passing. MIT licensed. Free.
What I'd Tell You to Build First
If you're going to build your own memory layer on OpenClaw — or extend BEE — three things in order of how much they'd have saved me:
Start with the prefilter. Not extraction — filtering. Garbage through the gate means garbage classification, garbage storage, garbage retrieval. The prefilter should be your first thing and your strictest thing.
Don't trust confidence scores alone. My regex extractor gave "ok" a score of 0.85. Scores measure how well something matches the extractor's model — not whether the thing is worth knowing. Gate on quality before you score.
Add echo guards before you need them. If you're building anything that uses OpenClaw's before_agent_start hook to inject content, plan for the loop immediately. You will build a self-referential system if you don't break it explicitly.
OpenClaw is 3 weeks old. The ecosystem is still being built. The memory layer is the most important unsolved piece — it's the difference between an agent that learns who you are and one that starts every session from zero.
BEE solves it. It's free. It's open source. And it's the first thing I'd install on any serious OpenClaw setup.
→ skysphere-labs/openclaw-bee on GitHub
Three weeks since OpenClaw launched. Three weeks of building, debugging, and shipping. This is what I learned.
Open source · MIT licensed · Free
BEE is live on GitHub →